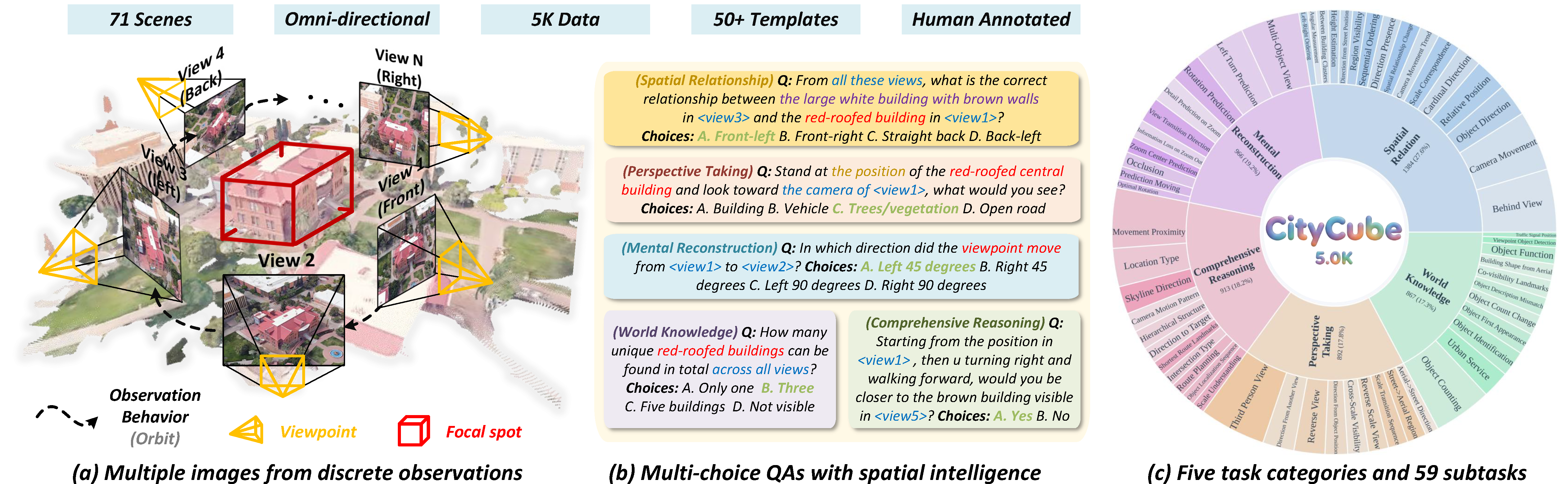
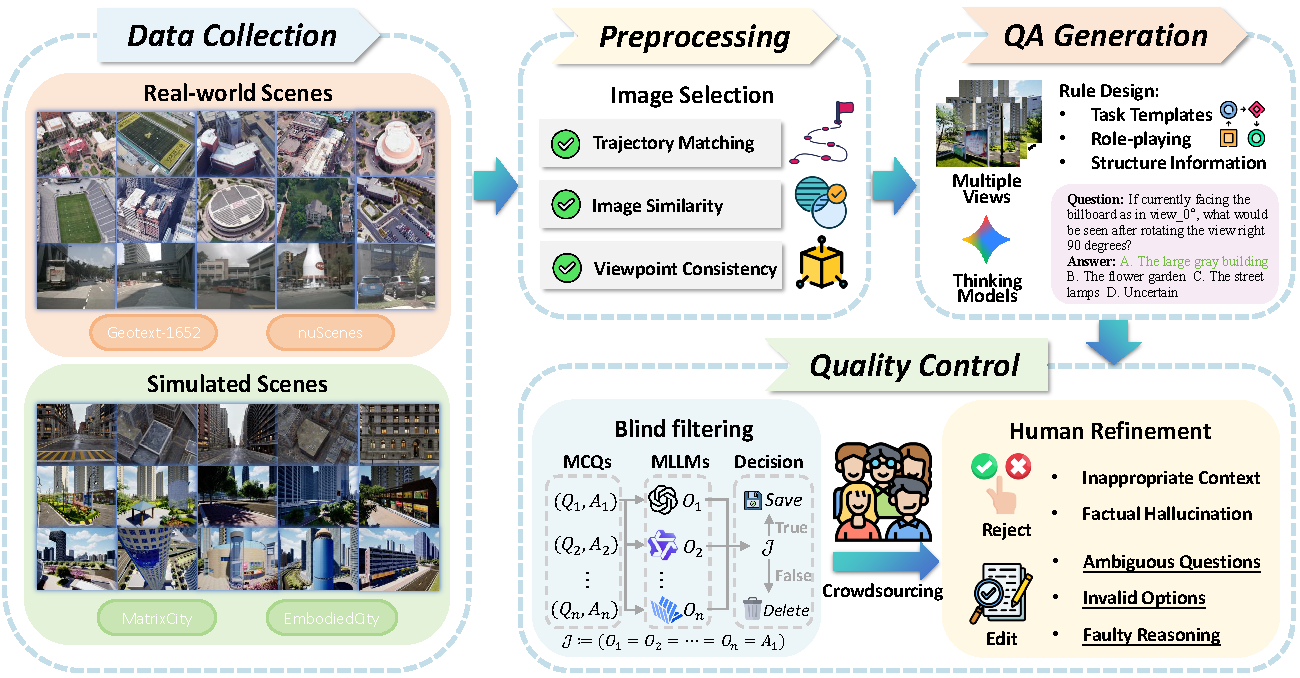
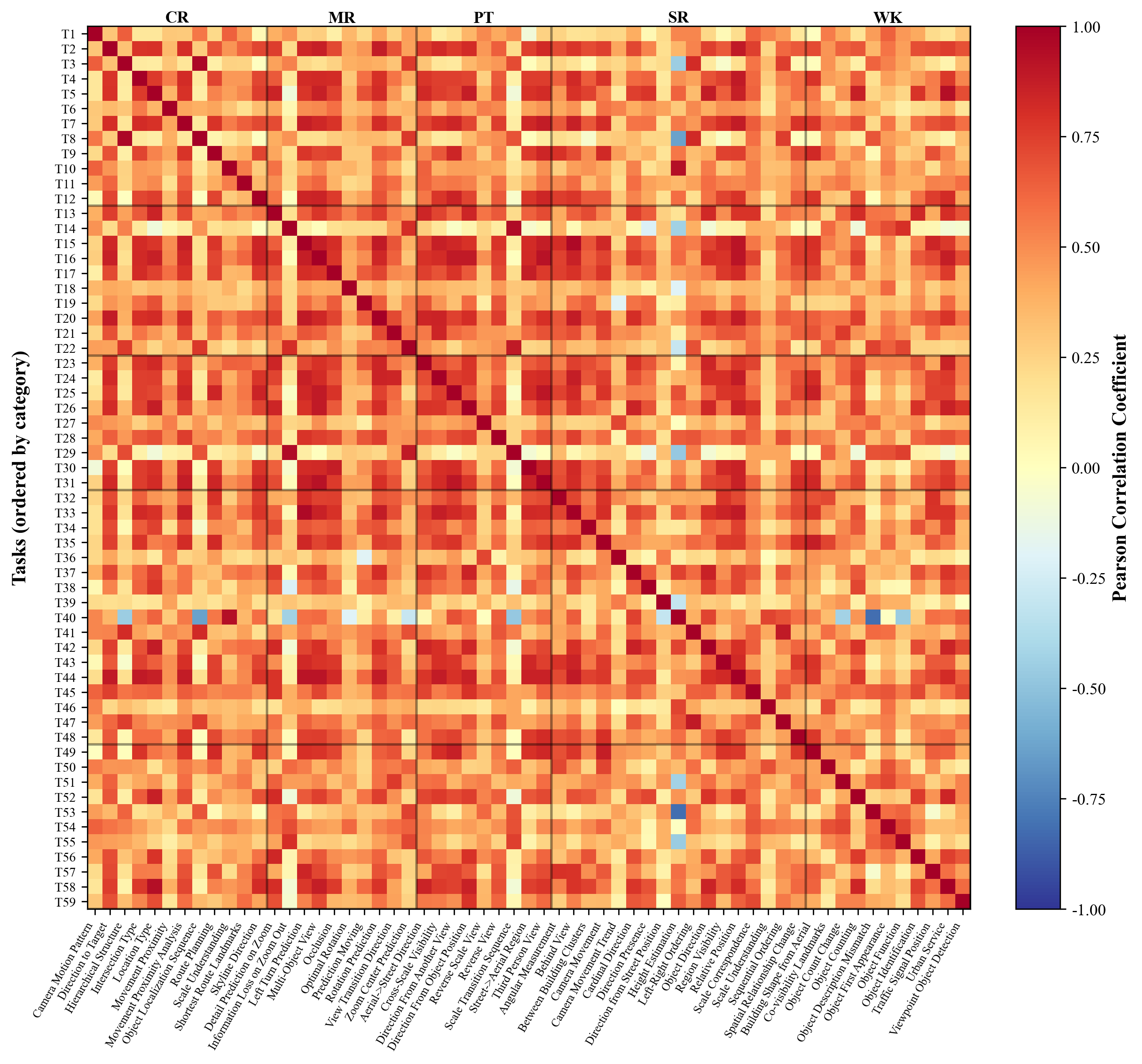
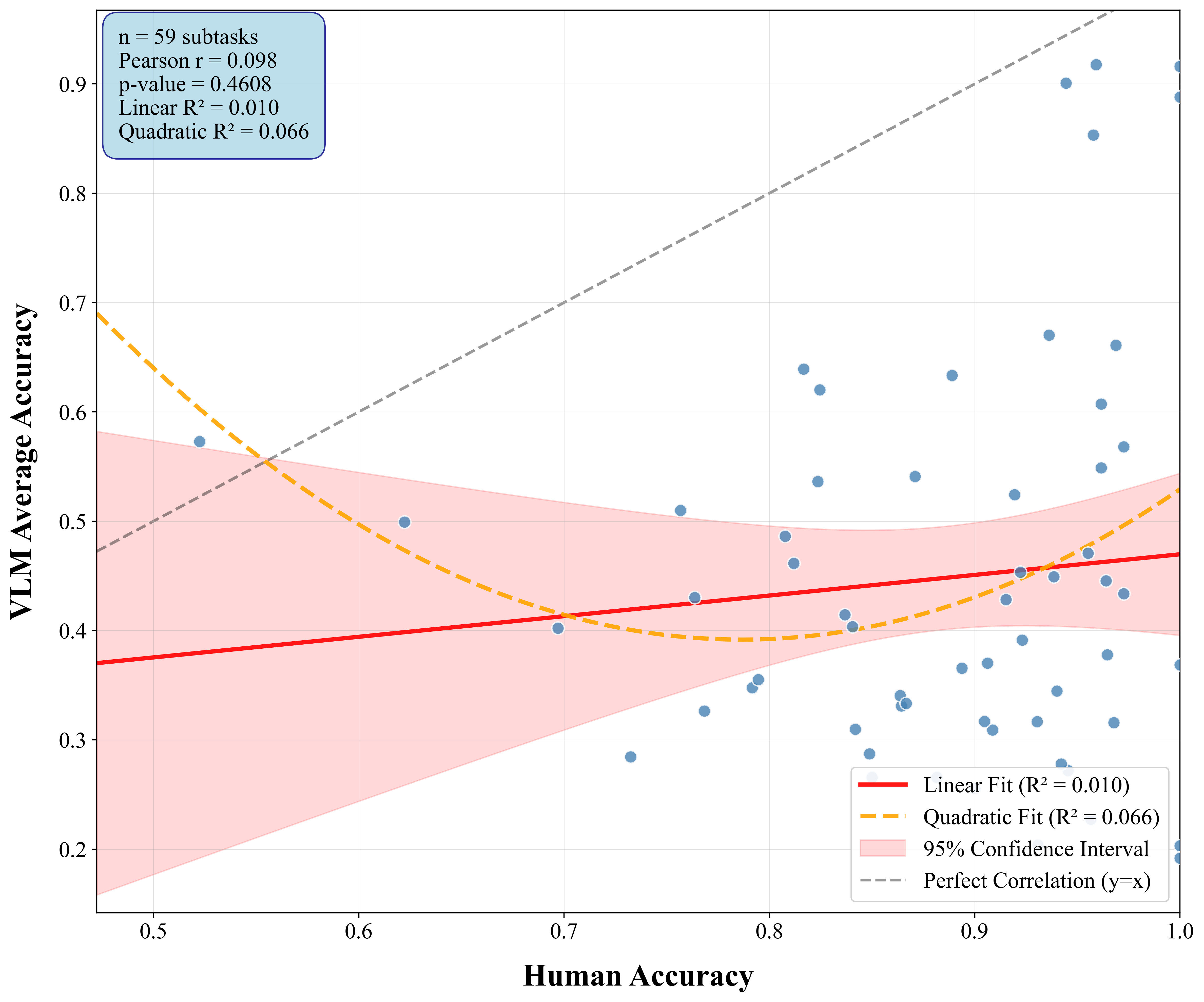
CityCube
Benchmarking Cross-view Spatial Reasoning on Vision-Language Models in Urban Environments
Haotian Xu1,2
Yue Hu1,2
Zhengqiu Zhu1,2
Chen Gao3
Ziyou Wang4
Junreng Rao1,2
Wenhao Lu1,2
Weishi Li1,2
Quanjun Yin1,2
Yong Li4
1 College of Systems Engineering, National University of Defense Technology
2 State Key Laboratory of Digital Intelligent Modeling and Simulation
3 BNRist, Tsinghua University
4 Department of Electronic Engineering, Tsinghua University
Under Review